NoSQL
- Disque 使用教程
- Redis 设计与实现
- Redis 命令参考
- Redis 设计与实现
- The Little Redis Book
- 带有详细注释的 Redis 2.6 代码
- 带有详细注释的 Redis 3.0 代码
- HBase 教程
- Memcached 教程
- The Little MongoDB Book
- The Little MongoDB Book 中文版
- Solr 教程
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。 虽然NoSQL才短短一年多的时间,但是不可否认,现在已经开始了第二代运动。尽管早期的堆栈代码只能算是一种实验,然而现在的系统已经更加的成熟、稳定。不过现在也面临着一个严酷的事实:技术越来越成熟——以至于原来很好的NoSQL数据存储不得不进行重写,也有少数人认为这就是所谓的2.0版本。这里列出一些比较知名的工具,可以为大数据建立快速、可扩展的存储库。
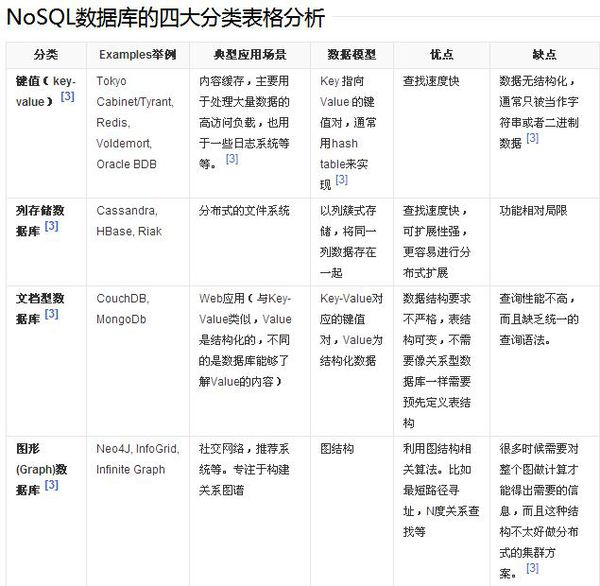
对于NoSQL并没有一个明确的范围和定义,但是他们都普遍存在下面一些共同特征: 不需要预定义模式:不需要事先定义数据模式,预定义表结构。数据中的每条记录都可能有不同的属性和格式。当插入数据时,并不需要预先定义它们的模式。 无共享架构:相对于将所有数据存储的存储区域网络中的全共享架构。NoSQL往往将数据划分后存储在各个本地服务器上。因为从本地磁盘读取数据的性能往往好于通过网络传输读取数据的性能,从而提高了系统的性能。 弹性可扩展:可以在系统运行的时候,动态增加或者删除结点。不需要停机维护,数据可以自动迁移。 分区:相对于将数据存放于同一个节点,NoSQL数据库需要将数据进行分区,将记录分散在多个节点上面。并且通常分区的同时还要做复制。这样既提高了并行性能,又能保证没有单点失效的问题。 异步复制:和RAID存储系统不同的是,NoSQL中的复制,往往是基于日志的异步复制。这样,数据就可以尽快地写入一个节点,而不会被网络传输引起迟延。缺点是并不总是能保证一致性,这样的方式在出现故障的时候,可能会丢失少量的数据。 BASE:相对于事务严格的ACID特性,NoSQL数据库保证的是BASE特性。BASE是最终一致性和软事务。 NoSQL数据库并没有一个统一的架构,两种NoSQL数据库之间的不同,甚至远远超过两种关系型数据库的不同。可以说,NoSQL各有所长,成功的NoSQL必然特别适用于某些场合或者某些应用,在这些场合中会远远胜过关系型数据库和其他的NoSQL。 NoSQL非关系型数据库这里对比下HBase, Memcached, MongoDB, Redis和Solr
1. Redis简介
1.Redis 是一个开源,先进的key-value存储,并用于构建高性能,可扩展的Web应用程序的完美解决方案。
Redis从它的许多竞争继承来的三个主要特点:
- Redis数据库完全在内存中,使用磁盘仅用于持久性。 相比许多键值数据存储,Redis拥有一套较为丰富的数据类型。
- Redis可以将数据复制到任意数量的从服务器。
2.Redis 优势
异常快速:Redis的速度非常快,每秒能执行约11万集合,每秒约81000+条记录。 - 支持丰富的数据类型:Redis支持最大多数开发人员已经知道像列表,集合,有序集合,散列数据类型。这使得它非常容易解决各种各样的问题,因为我们知道哪些问题是可以处理通过它的数据类型更好。
- 操作都是原子性:所有Redis操作是原子的,这保证了如果两个客户端同时访问的Redis服务器将获得更新后的值。
- 多功能实用工具:Redis是一个多实用的工具,可以在多个用例如缓存,消息,队列使用(Redis原生支持发布/订阅),任何短暂的数据,应用程序,如Web应用程序会话,网页命中计数等。
1.1. 常用命令
就DB来说,Redis成绩已经很惊人了,且不说memcachedb和Tokyo Cabinet之流,就说原版的memcached,速度似乎也只能达到这个级别。Redis根本是使用内存存储,持久化的关键是这三条指令:SAVE BGSAVE LASTSAVE … Redis命令用于在redis服务器上执行某些操作。 要在Redis服务器上运行的命令,需要一个Redis客户端。 Redis客户端在Redis的包,这已经我们前面安装使用过了。 语法 Redis客户端的基本语法如下:
例子 下面举例说明如何使用Redis客户端。 要启动redis客户端,打开终端,输入命令Redis命令行:redis-cli。这将连接到本地服务器,现在就可以运行各种命令了。$redis-cli
在上面的例子中,我们连接到本地机器上运行的Redis服务器,并且执行ping命令,来检查是否服务器正在运行。 远程服务器上运行命令 要在Redis远程服务器上运行的命令,需要通过同一个客户端redis-cli 连接到服务器 语法$redis-cli redis 127.0.0.1:6379> redis 127.0.0.1:6379> PING PONG
例如 下面的示例演示了如何连接到Redis主机:127.0.0.1,端口:6379 上的远程服务器,并加上验证密码为:mypass。$ redis-cli -h host -p port -a password$redis-cli -h 127.0.0.1 -p 6379 -a "mypass" redis 127.0.0.1:6379>redis 127.0.0.1:6379> PING PONG
2. MongoDB
2.1. 常用操作
链接
mongodb://admin:123456@localhost/test通过shell连接MongoDB服务:mongo扩展创建数据库
use db_name- 删除数据库 切换到要删除的数据库
use runoob执行删除命令db.dropDatabase() - 删除集合
db.collection.drop() - 插入文档
db.col.insert("key","value"})- 使用save()函数,如果原来的对象不存在,那他们都可以向collection里插入数据,如果已经存在,save会调用update更新里面的记录,而insert则会忽略操作
- insert可以一次性插入一个列表,而不用遍历,效率高,save则需要遍历列表,一个个插入。跟为详细的区别可以通过db.tb1.save和db.tb1.insert来查看对应的源码函数进行对比。
- 更新文档
db.col.update(<query>,<update>,{ "key1","value1", "key2","value2", "key3","value3" }) - 删除文档
db.col.remove({"key","value"}) - 查询文档
db.col.find({key1:value1, $or: [{key1: value1}, {key2:value2}]}).pretty() - 条件操作符 大于gt, 大于等于gte, 小于lt, 小于等于lte, 等于eq, 不等于ne
例如:
db.col.find({likes : {$lt :200, $gt : 100}}) - type 操作符 db.col.find({"title" : {$type : 2}})
- 读取指定数量的数据记录
Limit()和读取指定数量的数据外Skip()例如db.col.find().limit(1).skip(1) - 排序
db.col.find().sort({"KEY":1})1 为升序排列,而-1是用于降序排列。 - 索引
db.col.ensureIndex({open: 1, close: 1}, {background: true})1 为升序排列,而-1是用于降序排列。 - 聚合
aggregate()扩展
2.2. MongoDB安装
![enter description here][1]
MongoDB如何安装并设置成Windows服务的方法。
- 安装MongoDB下载
- 创建MongoDB数据库
mkdir data mongod -dbpath "C:\Program Files\MongoDB\data" - 将MongoDB设置成Windows服务
mongod -dbpath "C:\Program Files\MongoDB\data" -logpath "C:\Program Files\MongoDB\log\MongoDB.log" -install -serviceName "MongoDB"
![enter description here][2]
net start mongoDB # (开启服务)
net stop mongoDB # (关闭服务)
这个操作就是为了方便,每次开机MongoDB就自动启动了。
删除MongoDB Service、
mongod -dbpath "C:\Program Files\MongoDB\data" -logpath "C:\Program Files\MongoDB\log\MongoDB.log" -remove -serviceName "MongoDB"
2.3. MongoDB数据更新
- intert 单条插入 ![enter description here][3]
- bulk 批量
![enter description here][4]
- 并行
bulk.initializeUnorderdBulkOp() - 顺序
bulk.initializeOrderdBulkOp()bulk.insert() bulk.find.update() bulk.find.remove() # e:bulk.find({name:"lbb"}).remove(); - 执行
bulk.execute()
- 并行
remove 删除 ![enter description here][5]
以空间换时间 ![enter description here][6]
- update 更新 ![enter description here][7] ![enter description here][8] ![enter description here][9]